Archivo de la categoría: Teórico
Documentación Técnica
Hemos compilado en un documento todos los artículos académicos. A través de ellos hemos intentado explicar la tecnología desde un punto de vista académico y el modo en que la hemos implementado en Bheudek.

[Click para descargar]
Para cualquier pregunta o información puedes contactarnos en info@bheudek.com.
Ver todos los posts Teórico.
Ver todos los posts Teórico.
Beneficios de la Automatización del Software en el FinTech
El sector financiero se encuentra ante su mayor reto tecnológico: el fenómeno FinTech. Afrontar esta cambio, que implica a muchas áreas y tecnologías, requiere un enfoque global para evitar el caos operativo y tecnológico.
Ante este escenario, la automatización se presenta como la solución unificada que requiere el problema. Características como la semántica y la automatizacion de procesos ofrecen ventajas a los cambios que se abordarán en las diferentes áreas: servicios de negocio, servicios online y gestión de datos.
Ante este escenario, la automatización se presenta como la solución unificada que requiere el problema. Características como la semántica y la automatizacion de procesos ofrecen ventajas a los cambios que se abordarán en las diferentes áreas: servicios de negocio, servicios online y gestión de datos.
El sector financiero se halla sumergido en un proceso de renovación tecnológica. Las oportunidades que ofrecen las nuevas tecnologías y la irrupción de nuevos actores, muchos de ellos provenientes de otros sectores (Google, Amazon, Apple..), han obligado al sector a mover ficha.
El fenómeno FinTech está planteando actuaciones en áreas muy diversas y con tecnologías muy diversas, lo cual nos lleva a un escenario complejo donde se hace necesario que el problema sea abordado desde una perspectiva global, de lo contrario se corre el riesgo de entrar en un caos operativo y tecnológico.
Ante esta situación, las nuevas técnicas en la automatización del software se plantean como la mejor vía para afrontar este cambio.
El fenómeno FinTech está planteando actuaciones en áreas muy diversas y con tecnologías muy diversas, lo cual nos lleva a un escenario complejo donde se hace necesario que el problema sea abordado desde una perspectiva global, de lo contrario se corre el riesgo de entrar en un caos operativo y tecnológico.
Ante esta situación, las nuevas técnicas en la automatización del software se plantean como la mejor vía para afrontar este cambio.
La automatización del software eleva la solución técnica al nivel conceptual en el que opera el negocio. Este punto de vista más elevado es el que permite dar un enfoque más global y unificado al reto que plantea el FinTech.
Desde una visión más técnica, la automatización del software se apoya en la creación de lenguajes de programación más abstractos que permiten automatizar los detalles técnicos y dotar al sistema de una mayor riqueza semántica. En ámbitos técnicos, estos lenguajes se denominan DSLs y las herramientas para gestionarlos Language Workbench.
Ventajas.
1.Automatización de procesos.
Trabajar en un nivel más abstracto permite automatizar procesos técnicos pero también a procesos tradicionales de negocio. Motores de decisión, ofertas basadas en riesgo, predicción de fallidos y detección del fraude son ejemplos de procesos que pueden verse mejorados bajo la perspectiva de la automatización.
2.Semántica.
La nueva forma de definir los lenguajes de programación, a partir de los conceptos que los estructuran, abre las puertas a la Representación del Conocimiento. Esta disciplina, tradicionalmente de la inteligencia artificial, se aplica cada vez más al tratamiento de datos (visualización, búsqueda, análisis, toma de decisiones …) y en el futuro será fundamental en cualquier proceso de análisis y de interacción, bien con clientes, bien con otros sistemas. XBRL (lenguaje de presentación de informes de negocio extensible) y FIBO (ontología del negocio financiero) son ejemplos de aplicación de la semántica en el sector financiaro.
3.Menor complejidad técnica.
Nuevamente, el mayor nivel de abstracción de los lenguajes nos permite resolver, de manera automática, gran parte de los detalles técnicos que requieren las diferentes soluciones. Conseguir automatizar esta complejidad redunda en la calidad, seguridad, estandarización y otras características del software.
4.Multi-plataforma.
Una vez que tenemos el dominio de los lenguajes de programación, un mismo desarrollo puede traducirse a múltiples plataformas, sin necesidad de tener que llevar a cabo un nuevo proyecto para cada nuevo dispositivo.
5.Orientación a negocio.
Los lenguajes de programación se hacen más cercanos al negocio, lo cual permite a los desarrolladores enfocarse en dar una solución desde el punto de vista propiamente del negocio y no desde una perspectiva técnica. A su vez esto derriba la barrera que ha existido siempre entre las áreas de desarrollo y el resto de áreas de la empresa.
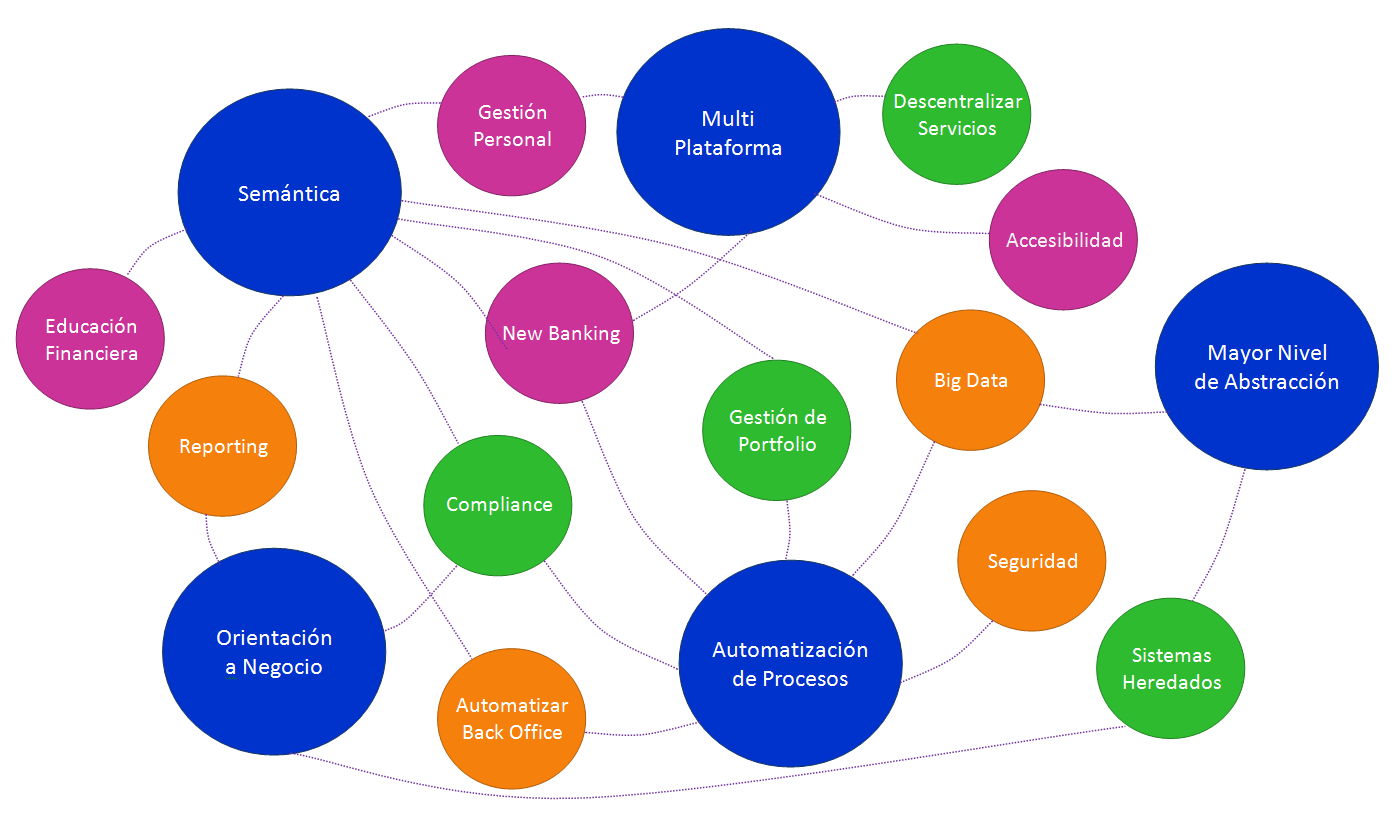
Áreas beneficiadas.
El FinTech actúa en múltiples áreas en las que la automatización puede aportar sus ventajas. Las agrupamos en tres bloque principales: servicios de negocio, servicios online y gestión de datos.
1.Servicios de negocio.
La demanda de nuevos servicios por parte del cliente y la búsqueda de mejoras en la productividad, está llevando al sector a actuar sobre sus estructuras más tradicionales. Los puntos en los que la automatización aporta ventajas son:
Ventajas.
1.Automatización de procesos.
Trabajar en un nivel más abstracto permite automatizar procesos técnicos pero también a procesos tradicionales de negocio. Motores de decisión, ofertas basadas en riesgo, predicción de fallidos y detección del fraude son ejemplos de procesos que pueden verse mejorados bajo la perspectiva de la automatización.
2.Semántica.
La nueva forma de definir los lenguajes de programación, a partir de los conceptos que los estructuran, abre las puertas a la Representación del Conocimiento. Esta disciplina, tradicionalmente de la inteligencia artificial, se aplica cada vez más al tratamiento de datos (visualización, búsqueda, análisis, toma de decisiones …) y en el futuro será fundamental en cualquier proceso de análisis y de interacción, bien con clientes, bien con otros sistemas. XBRL (lenguaje de presentación de informes de negocio extensible) y FIBO (ontología del negocio financiero) son ejemplos de aplicación de la semántica en el sector financiaro.
3.Menor complejidad técnica.
Nuevamente, el mayor nivel de abstracción de los lenguajes nos permite resolver, de manera automática, gran parte de los detalles técnicos que requieren las diferentes soluciones. Conseguir automatizar esta complejidad redunda en la calidad, seguridad, estandarización y otras características del software.
4.Multi-plataforma.
Una vez que tenemos el dominio de los lenguajes de programación, un mismo desarrollo puede traducirse a múltiples plataformas, sin necesidad de tener que llevar a cabo un nuevo proyecto para cada nuevo dispositivo.
5.Orientación a negocio.
Los lenguajes de programación se hacen más cercanos al negocio, lo cual permite a los desarrolladores enfocarse en dar una solución desde el punto de vista propiamente del negocio y no desde una perspectiva técnica. A su vez esto derriba la barrera que ha existido siempre entre las áreas de desarrollo y el resto de áreas de la empresa.
Áreas beneficiadas.
El FinTech actúa en múltiples áreas en las que la automatización puede aportar sus ventajas. Las agrupamos en tres bloque principales: servicios de negocio, servicios online y gestión de datos.
1.Servicios de negocio.
La demanda de nuevos servicios por parte del cliente y la búsqueda de mejoras en la productividad, está llevando al sector a actuar sobre sus estructuras más tradicionales. Los puntos en los que la automatización aporta ventajas son:
Descentralización. Para poder llevar a cabo la descentralización de servicios (call centers, back office, etc), es necesario migrar hacia el entorno web, lo cual resulta un reto importante porque los sistemas deben mantener las características de seguridad, velocidad y manejabilidad de las aplicaciones de escritorio tradicionales. La automatización nos permite crear, de manera eficiente, Aplicativos Web de Escritorio.
Gestión del portfolio. La automatización de procesos tradicionales nos permite una gestión más optimizada. Por otro lado, la semántica nos permite la gestión unificada de portfolios heterogéneos y la integración de portfolios externos.
Compliance. La semántica, junto con el uso de lenguajes orientados a negocio, facilitan los procesos de análisis y documentación de auditoría. A su vez, la automatización de procesos es la mejor vía para solucionar problemas de compliance.
Sistemas heredados (legacy). El mayor nivel de abstracción de los lenguajes nos permite diseñar, de manera simple, interfaces con los sistemas ya existentes.
Gestión del portfolio. La automatización de procesos tradicionales nos permite una gestión más optimizada. Por otro lado, la semántica nos permite la gestión unificada de portfolios heterogéneos y la integración de portfolios externos.
Compliance. La semántica, junto con el uso de lenguajes orientados a negocio, facilitan los procesos de análisis y documentación de auditoría. A su vez, la automatización de procesos es la mejor vía para solucionar problemas de compliance.
Sistemas heredados (legacy). El mayor nivel de abstracción de los lenguajes nos permite diseñar, de manera simple, interfaces con los sistemas ya existentes.
2.Servicios online.
La aparición de nuevos dispositivos, la mejora en las comunicaciones y la nueva cultura digital han hecho que las entidades abran sus puertas para permitir una gestión más directa por parte de sus clientes. Nuevamente la automatización ofrece beneficios en éste área:
La aparición de nuevos dispositivos, la mejora en las comunicaciones y la nueva cultura digital han hecho que las entidades abran sus puertas para permitir una gestión más directa por parte de sus clientes. Nuevamente la automatización ofrece beneficios en éste área:
Accesibilidad. La multi-plataforma permite multiplicar las vías de acceso de los clientes a sus datos.
Promover la educación financiera. La semántica dota a los sistemas de unas capacidades de visualización y documentación que facilitan su manejo y entendimiento.
Gestión personal. Como resultado de las puntos anteriores, el cliente pasa a tener una gestión más personal de sus datos y sus activos. Como hemos dicho, la semántica juega un papel fundamental en la interacción con el cliente.
New Banking. Multi-plataforma, semántica y automatización de procesos permiten nuevas líneas de negocio como: ofertas personalizadas, plataformas de pago, cripto-monedas, análisis proactivos de riesgo y otros.
Promover la educación financiera. La semántica dota a los sistemas de unas capacidades de visualización y documentación que facilitan su manejo y entendimiento.
Gestión personal. Como resultado de las puntos anteriores, el cliente pasa a tener una gestión más personal de sus datos y sus activos. Como hemos dicho, la semántica juega un papel fundamental en la interacción con el cliente.
New Banking. Multi-plataforma, semántica y automatización de procesos permiten nuevas líneas de negocio como: ofertas personalizadas, plataformas de pago, cripto-monedas, análisis proactivos de riesgo y otros.
3.Gestión de datos.
La interacción más directa con el cliente y los nuevos metodologías para procesar esa informacion han revolucionado el tratamiento de los datos y las tradicionales técnicas de CRM. En este último apartado la automatización también ofrece ventajas:
La interacción más directa con el cliente y los nuevos metodologías para procesar esa informacion han revolucionado el tratamiento de los datos y las tradicionales técnicas de CRM. En este último apartado la automatización también ofrece ventajas:
Automatización del back office. La automatización del back office pasa por la automatización de su workflow. Las posibilidades que ofrece la semántica en el diseño de motores de decisión más «inteligentes», junto con la automatización de procesos, son líneas fundamentales para conseguir este objetivo.
Reporting. En general el reporting cada vez más tiende a la semántica, un ejemplo de ello es XBRL.
Seguridad. La automatización de procesos permite un tratamiento más seguro de los datos.
Big Data. Podemos resumir, ya que este punto requeriría un artículo entero, que la semántica, la automatización de procesos y un mayor nivel de abstracción nos permiten, por un lado, manejar la variabilidad de los datos y por otro, mitigar los riesgos que supone la desestructuración asociada al Big Data .
Reporting. En general el reporting cada vez más tiende a la semántica, un ejemplo de ello es XBRL.
Seguridad. La automatización de procesos permite un tratamiento más seguro de los datos.
Big Data. Podemos resumir, ya que este punto requeriría un artículo entero, que la semántica, la automatización de procesos y un mayor nivel de abstracción nos permiten, por un lado, manejar la variabilidad de los datos y por otro, mitigar los riesgos que supone la desestructuración asociada al Big Data .
Conclusión.
El sector financiero se encuentra ante uno de los retos tecnológicos más grandes de toda su historia, reto en el que se ven afectadas múltiples áreas y tecnologías.
La automatización del software aporta el enfoque general y unificado que requiere este escenario, de lo contrario, las actuaciones individualizadas pueden llevar a las compañías a un panorama tecnológico difícilmente gobernable.
Aplicaciones Web de Escritorio
Más allá de la publicidad o la identidad digital, las empresas cada vez más ven en la web la vía para mejorar su productividad y servicios: objetivos como descentralizar la gestión (back offices) o dotar a los clientes de una actividad directa online son ejemplos de ello.
Aunque la web no fue diseñada en origen para una interacción dinámica y bidireccional, la aparición de nuevas las tecnologías y la mejora en los navegadores, nos permiten diseñar aplicaciones cada vez más cercanas a las tradicionales aplicaciones de escritorio.
Estas aplicaciones web de escritorio son diferentes a las páginas web y a los aplicaciones web (e-commerce, por ejemplo), porque se enfocan a usuarios que necesitan una interacción continua, prolongada y ágil. Pongamos como ejemplo cualquier usuario de call center: atención al cliente, servicio técnico, gestión de recobros, etc.
Requisitos de una aplicación web de escritorio
Aunque la web no fue diseñada en origen para una interacción dinámica y bidireccional, la aparición de nuevas las tecnologías y la mejora en los navegadores, nos permiten diseñar aplicaciones cada vez más cercanas a las tradicionales aplicaciones de escritorio.
Estas aplicaciones web de escritorio son diferentes a las páginas web y a los aplicaciones web (e-commerce, por ejemplo), porque se enfocan a usuarios que necesitan una interacción continua, prolongada y ágil. Pongamos como ejemplo cualquier usuario de call center: atención al cliente, servicio técnico, gestión de recobros, etc.
Requisitos de una aplicación web de escritorio
- Teclado. Es indispensable que la aplicación pueda ser gobernada por el teclado y no solamente por el ratón. Tabulador, intro, flechas, etc.
- Velocidad. No solo por motivos de comodidad sino de productividad.
- Seguridad. Los datos con los que tratan estas aplicaciones son muy sensibles.
- Sin efecto parpadeo. La carga de contenido ha de ser parcial y dinámica, el refresco continuo de toda la página produce un efecto incómodo e insano.
- Estética agradable y estándar. Debe ser limpia y nunca recargada.
Consejos para conseguirlo
- Patrón SPA (Single Page Application). Se trata de un patrón de página web única donde los contenidos se van cargando dinámicamente. Permite políticas como carga inicial de ficheros (js, css, imágenes, etc), control de sesión compartido, mayor procesamiento en el cliente, etc.
- Interfaz estándar en todo el aplicativo. Las pantallas, los botones, las pestañas, los grids de datos y demás controles han de tener un aspecto y operativa común a lo largo del aplicativo.
- Framework JavaScrtipt. Necesario para estandarizar la interfaz y dotarla de los servicios para gestionar los controles y ventanas. Por motivos de seguridad y adaptabilidad se aconseja que sea desarrollo propio y encapsulado en un único objeto.
- Control de eventos de teclado. El framework debe implementarlos y asociarlos a los controles.
- AJAX. La vía para el dinamismo.
- Minimizar uso de la red. El trasiego de datos debe ser el mínimo, aunque eso suponga mayor procesamiento en el lado del cliente. Estándares de intercambio como JSON son aconsejables.
- Pantallas modales. Mejoran la experiencia de usuario y el dinamismo del aplicativo.
- Uso de imágenes sprites. Permiten cargar todas las imágenes de la aplicación al principio.
Un desarrollo automatizado de la interfaz de usuario apoyada en un framework js potente es el mejor camino para cumplir los objetivos anteriores.
Conclusión
 Cuando hablamos de apps de escritorio hablamos de aplicaciones con unos requisitos muy exigentes ya que son la herramienta de trabajo en la que los usuarios pasarán gran parte de su tiempo.
Cuando hablamos de apps de escritorio hablamos de aplicaciones con unos requisitos muy exigentes ya que son la herramienta de trabajo en la que los usuarios pasarán gran parte de su tiempo.
Podrán seguir apareciendo nuevos dispositivos y nuevas maneras de interactuar con los sistemas, pero cuando hablamos de interacción, requisitos tradicionales como el teclado, la velocidad, la seguridad y la ergonomía se hacen imprescindibles.
Ver todos los posts Teórico.
Conclusión
 Cuando hablamos de apps de escritorio hablamos de aplicaciones con unos requisitos muy exigentes ya que son la herramienta de trabajo en la que los usuarios pasarán gran parte de su tiempo.
Cuando hablamos de apps de escritorio hablamos de aplicaciones con unos requisitos muy exigentes ya que son la herramienta de trabajo en la que los usuarios pasarán gran parte de su tiempo.Podrán seguir apareciendo nuevos dispositivos y nuevas maneras de interactuar con los sistemas, pero cuando hablamos de interacción, requisitos tradicionales como el teclado, la velocidad, la seguridad y la ergonomía se hacen imprescindibles.
Ver todos los posts Teórico.
Resumen de la Metodología
A lo largo de diversas publicaciones hemos ido mostrando los diferentes elementos en que se apoya la automatización y sus beneficios. Resumimos aquí, de manera ordenada, dicha metodología:
- Automatizacion de Software. Introduccion.. Primera aproximación a la tecnología..
- ¿Por qué generación de código?. Es esta primera publicación explicamos cuales son los motivos que llevan a elegir el camino de la generación de código para mejorar el proceso de desarrollo de software.
- Buenas Prácticas en la Generación de Código. Conocido lo qué es y el por qué de su uso, mostramos unos consejos sobre cómo generar código correctamente.
- 10 Ventajas de la Generación de Código. Lista de ventajas.
- DSLs. Siguiendo el camino de la automatización, pasamos a explicar lo qué son los Lenguajes Específicos de Dominio (DSL) y la ventajas que nos aportan. Los DSLs son necesarios si queremos que nuestro proceso de automatización llegue al grado más alto.
- Language Workbench. Para diseñar y usar los DSLs necesitamos herramientas que nos provean de estos servicios. Estas herramientas se denominan técnicamente Language Workbench, y nos permiten, además, integrar todo el proceso de desarrollo e incluso entrar en el área de la representación del conocimiento.
- Representación del Conocimiento y Automatización de Software. Profundizamos más en este área.
- Diseñadores de Lenguajes. Características de este nuevo perfil requerido en el desarrollo de software.
- Frameworks: la Media Naranja de la Generación de Código. Introduccion y ventajas de los Frameworks y colaboración con la generación de código.
- Automatización: Proceso Completo. Compilación del proceso de desarrollo.
Automatización: Proceso Completo
A lo largo de diferentes artículos hemos ido viendo el conjunto de elementos que forman la metodología, compilamos en éste todo el proceso.
Generación de código
A través del Language Workbench, una vez definidos los lenguajes (DSLs), realizamos el proceso de programación. Y a medida que vayamos avanzando iremos generando código para compilarlo y ver el resultado en el aplicativo final.
Siempre que utilicemos lenguajes que soportan clases parciales, clases abstractas, tipos genéricos, delegados, etc., podemos generar el código sin peligro ya que lo haremos en ficheros separados, sin riesgo de pisar código manual o de FWs. En caso contrario deberemos utilizar otro tipo de estrategias para evitar que esto ocurra.
Fusión con Frameworks
Como en el caso anterior, dependiendo de los lenguajes finales que utilicemos, la fusión será más o menos simple. En el caso de lenguajes que soporten FWs (clases abstractas, parciales, etc) no se requiere tal fusión porque lo soluciona la propia sintaxis del lenguaje.
En otro tipo de lenguajes habrá que ajustar alguna funcionalidad o algún fichero de configuración, lo cual podrá ser también automatizado por el propio LW.
Extensiones manuales
En la mayoría de los casos existirán ciertas funcionalidades que no conviene automatizar, de lo contrario complicaríamos nuestros DSLs perdiendo, por tanto, parte de su potencia.
Lo ideal sería definir, en la propia herramienta, esos lenguajes de extensión teniendo integrado todo el desarrollo en la herramienta. En caso contrario podremos programar estas extensiones en el propio lenguaje final en el que generamos el código.
Si añadimos las extensiones en el lenguaje final, nuevamente será interesante buscar un enfoque de FWs, esto es, hacer que el propio código generado tenga una estructura extensible y así podamos tener las partes manuales en ficheros diferentes, evitando el riesgo de pérdida o substitución.

Generación de código
A través del Language Workbench, una vez definidos los lenguajes (DSLs), realizamos el proceso de programación. Y a medida que vayamos avanzando iremos generando código para compilarlo y ver el resultado en el aplicativo final.
Siempre que utilicemos lenguajes que soportan clases parciales, clases abstractas, tipos genéricos, delegados, etc., podemos generar el código sin peligro ya que lo haremos en ficheros separados, sin riesgo de pisar código manual o de FWs. En caso contrario deberemos utilizar otro tipo de estrategias para evitar que esto ocurra.
Fusión con Frameworks
Como en el caso anterior, dependiendo de los lenguajes finales que utilicemos, la fusión será más o menos simple. En el caso de lenguajes que soporten FWs (clases abstractas, parciales, etc) no se requiere tal fusión porque lo soluciona la propia sintaxis del lenguaje.
En otro tipo de lenguajes habrá que ajustar alguna funcionalidad o algún fichero de configuración, lo cual podrá ser también automatizado por el propio LW.
Extensiones manuales
En la mayoría de los casos existirán ciertas funcionalidades que no conviene automatizar, de lo contrario complicaríamos nuestros DSLs perdiendo, por tanto, parte de su potencia.
Lo ideal sería definir, en la propia herramienta, esos lenguajes de extensión teniendo integrado todo el desarrollo en la herramienta. En caso contrario podremos programar estas extensiones en el propio lenguaje final en el que generamos el código.
Si añadimos las extensiones en el lenguaje final, nuevamente será interesante buscar un enfoque de FWs, esto es, hacer que el propio código generado tenga una estructura extensible y así podamos tener las partes manuales en ficheros diferentes, evitando el riesgo de pérdida o substitución.

Componentes del servidor web
Building
Una vez que tenemos todo el código: FWs, generado, extensiones manuales, ficheros de configuración y otros, un proceso automático se encargará de su fusión, si fuera necesario, de su compilación y de su publicación.
Dependiendo del sistema operativo tendremos diferentes herramientas para hacerlo, aunque lo más común en todos ellos es usar ficheros de instrucciones batch que realiza todos los pasos del proceso.
Para concluir indicar que hemos detallado el proceso tal y como se encuentra en este momento, pero cabe resaltar que es una tecnología en constante evolución y que persigue integrar todo el proceso en el propio LW: lenguajes, debug, fusión, building, etc.
Ver todos los posts Teórico.
Dependiendo del sistema operativo tendremos diferentes herramientas para hacerlo, aunque lo más común en todos ellos es usar ficheros de instrucciones batch que realiza todos los pasos del proceso.
Para concluir indicar que hemos detallado el proceso tal y como se encuentra en este momento, pero cabe resaltar que es una tecnología en constante evolución y que persigue integrar todo el proceso en el propio LW: lenguajes, debug, fusión, building, etc.
Ver todos los posts Teórico.
Frameworks: la Media Naranja de la Generación de Código
Podemos definir un Framework (FW) como una estructura software con funcionalidades genéricas las cuales pueden ser adaptadas o enriquecidas para obtener un aplicativo final.
Comúnmente pueden ser confundidos con las librerías, pero se trata de un enfoque totalmente diferente. He aquí las principales características que definen esta diferencia:
Comúnmente pueden ser confundidos con las librerías, pero se trata de un enfoque totalmente diferente. He aquí las principales características que definen esta diferencia:
- La inversión de control. El flujo de control lo define el FW y no el aplicativo que usa sus servicios. Esto también es conocido como el principio de Hollywood: “no nos llames, nosotros te llamaremos”.
- Extensibilidad. Algunas funcionalidades del FW no están “cerradas” como sucede en las librerías, al contrario están diseñadas para ser particularizadas según el problema particular que deban resolver.
- Comportamiento predeterminado. los FWs poseen un comportamiento global predeterminado, comportamiento que define el flujo de control. Como se ha visto antes, la extensión es lo que permite adaptar el comportamiento global al problema particular que cada aplicativo requiera.
Los frameworks son la base de las arquitecturas plug-in y de los sistemas enfocados a ecosistemas de desarrollo (facebook, twitter, amazon…), pero sobretodo son la arquitectura perfecta para hacer de base al código generado.
Técnicamente, dependiendo del lenguaje de programación que usemos, habrá varias formas de implementarlo. En lenguajes que lo permitan lo mejor es apoyarse en clases abstractas, clases parciales, delegados y tipos genéricos. En caso contrario se pueden usar otras estrategias como: intérpretes, funciones intermedias, tipo patrón visitor, que resuelvan la llamada y otros.
Ventajas en la generación de código
Estas son las características que aconsejan su uso:
Técnicamente, dependiendo del lenguaje de programación que usemos, habrá varias formas de implementarlo. En lenguajes que lo permitan lo mejor es apoyarse en clases abstractas, clases parciales, delegados y tipos genéricos. En caso contrario se pueden usar otras estrategias como: intérpretes, funciones intermedias, tipo patrón visitor, que resuelvan la llamada y otros.
Ventajas en la generación de código
Estas son las características que aconsejan su uso:
- Extensible. Permiten realizar el trabajo en dos partes, lo cual facilita la definición del generador de código.
- Estructurado. Diseñar por un lado la parte genérica y en el generador la particular, permite tener una arquitectura mejor estructurada.
- Seguridad. Permite tener físicamente separados el código manual y el código generado, lo cual evita perdidas de código.
- Reutilizable. Una vez definido un FW podemos utilizarle en diferentes proyectos, facilitando nuevamente el desarrollo del generador.
- Legibilidad. La separación de lo genérico y lo particular facilita el entendimiento del código.
Conclusión
Cuando se aborda la generación de código se suele pensar que se va a generar el sistema al 100%. Una vez que se profundiza en ello se ve que es complejo además de ser un error de diseño y una distribución de trabajo desequilibrada.
Para conseguir un buen diseño arquitectónico y una buena distribución del trabajo los frameworks se muestran como la media naranja ideal para nuestro sistemas generados.
Por último, es aconsejable que el código generado tenga también una estructura de framework, esto nos permite poder implementar aquellas particularidades que no convenga automatizar y a su vez permite que nuestros sistemas puedan ser extendidos por un ecosistema de desarrolladores.
Ver todos los posts Teórico.
Cuando se aborda la generación de código se suele pensar que se va a generar el sistema al 100%. Una vez que se profundiza en ello se ve que es complejo además de ser un error de diseño y una distribución de trabajo desequilibrada.
Para conseguir un buen diseño arquitectónico y una buena distribución del trabajo los frameworks se muestran como la media naranja ideal para nuestro sistemas generados.
Por último, es aconsejable que el código generado tenga también una estructura de framework, esto nos permite poder implementar aquellas particularidades que no convenga automatizar y a su vez permite que nuestros sistemas puedan ser extendidos por un ecosistema de desarrolladores.
Ver todos los posts Teórico.
Diseñadores de Lenguajes
Una vez que disponemos de una herramienta para diseñar lenguajes de forma ágil, viene la tarea más difícil: diseñarlos.
El diseño de un buen lenguaje es la parte principal del proceso ya que será la herramienta de los desarrolladores y lo que va a albergar la inteligencia semántica del sistema.
Asimismo, dado que los conceptos que estructuran el lenguaje forman en sí mismo el modelo, antes de diseñarlo es necesario conocer bien el dominio que se quiere modelar.
Características de un buen lenguaje
El diseño de un buen lenguaje es la parte principal del proceso ya que será la herramienta de los desarrolladores y lo que va a albergar la inteligencia semántica del sistema.
Asimismo, dado que los conceptos que estructuran el lenguaje forman en sí mismo el modelo, antes de diseñarlo es necesario conocer bien el dominio que se quiere modelar.
Características de un buen lenguaje
- Alto nivel de abstracción. Mientras mayor sea el nivel, más potente será el lenguaje y mayor carga semántica tendrán sus conceptos. Asimismo, un alto nivel de abstracción denota un alto conocimiento del dominio que se modela.
- Simple. Debe ser fácil de utilizar y de leer. Un lenguaje simple suele ser sinónimo de un alto nivel de abstracción.
- Diferentes niveles de complejidad. A la vez que debe ser simple, también debe permitir vías para profundizar en el detalle por parte de aquellos que lo necesiten.
- Estética agradable.
- Semánticamente potente. Para que un lenguaje sea productivo simplemente es necesario dotar a los conceptos de su representación gráfica y su traducción a lenguajes tradicionales, pero si queremos que realmente sea completo, debemos dotar a los conceptos de más interpretaciones semánticas: auto documentación, auto validación, reglas de inferencia, etc.
Requisitos de un buen diseñador
A partir de las características de un buen lenguaje podemos inducir los requisitos:
A partir de las características de un buen lenguaje podemos inducir los requisitos:
- Orientación a negocio. Conocer bien el dominio para diseñar el lenguaje requiere un alto interés por conocer todos los procesos que lo rigen.
- Capacidad de abstracción. Conocido el dominio, se requiere una capacidad analítica que permita identificar, con el mayor nivel de abstracción posible, su más pura esencia.
- Enfoque hacia la semántica. El lenguaje ha de diseñarse con el objetivo de dotarle de una alta capacidad de representar el conocimiento.
- Cualidades enfocadas a la simpleza y la estética.
Conclusión
Este nuevo paradigma de desarrollo requiere un perfil particular para diseñar los lenguajes, donde no solo son importantes las antiguas cualidades analíticas sino que se han de añadir cualidades de usabilidad y de representación del conocimiento.
Inicialmente puede parecer complejo pero al fin y al cabo forma parte de la evolución de la tecnología, donde los perfiles que más aportan son aquellos que tienen mayor capacidad de abstracción.
Ver todos los posts Teórico.
Este nuevo paradigma de desarrollo requiere un perfil particular para diseñar los lenguajes, donde no solo son importantes las antiguas cualidades analíticas sino que se han de añadir cualidades de usabilidad y de representación del conocimiento.
Inicialmente puede parecer complejo pero al fin y al cabo forma parte de la evolución de la tecnología, donde los perfiles que más aportan son aquellos que tienen mayor capacidad de abstracción.
Ver todos los posts Teórico.
Representación del Conocimiento y Automatización de Software
La representación del conocimiento es una disciplina que persigue la representación de la información del mundo real de una manera que pueda ser interpretada por las máquinas para resolver, mediante inferencia, problemas complejos.
Tradicionalmente ha sido una disciplina de la inteligencia artificial y últimamente ha adquirido gran relevancia por su utilización en el ámbito de la semántica. El proyecto de la Web Semántica, liderado por la W3C, es un claro ejemplo de ello.
Aunque existen muchos enfoques para la representación del conocimiento, comúnmente todos persiguen: definir los conceptos, las relaciones y las reglas que definen la información. Mediante los diferentes conceptos podemos clasificar la información y mediante las relaciones y reglas podemos inferir (razonar) sobre ella. Por lo tanto, en vez de tener información “plana” tendremos además una meta-información que nos permitiría procesarla.
Desde la perspectiva de los lenguajes
En anteriores publicaciones vimos como los Language Workbenches definen los lenguajes mediante las sintaxis abstracta y concreta y las semánticas estáticas y dinámicas. Si nos damos cuenta esa definición sería la meta-información que hace que un programa sea una representación del conocimiento y que, por tanto, podemos utilizar todo el potencial que esta disciplina nos aporta.
Se suele pensar en los Language Workbenches como generadores de código pero, enfocados desde el punto de vista de la representación del conocimiento y de la semántica, pueden ofrecernos muchos más servicios. Enumeramos algunos:
Tradicionalmente ha sido una disciplina de la inteligencia artificial y últimamente ha adquirido gran relevancia por su utilización en el ámbito de la semántica. El proyecto de la Web Semántica, liderado por la W3C, es un claro ejemplo de ello.
Aunque existen muchos enfoques para la representación del conocimiento, comúnmente todos persiguen: definir los conceptos, las relaciones y las reglas que definen la información. Mediante los diferentes conceptos podemos clasificar la información y mediante las relaciones y reglas podemos inferir (razonar) sobre ella. Por lo tanto, en vez de tener información “plana” tendremos además una meta-información que nos permitiría procesarla.
Desde la perspectiva de los lenguajes
En anteriores publicaciones vimos como los Language Workbenches definen los lenguajes mediante las sintaxis abstracta y concreta y las semánticas estáticas y dinámicas. Si nos damos cuenta esa definición sería la meta-información que hace que un programa sea una representación del conocimiento y que, por tanto, podemos utilizar todo el potencial que esta disciplina nos aporta.
Se suele pensar en los Language Workbenches como generadores de código pero, enfocados desde el punto de vista de la representación del conocimiento y de la semántica, pueden ofrecernos muchos más servicios. Enumeramos algunos:
- Generar baterías de pruebas.
- Generar cargas iniciales de datos. Relleno de estructuras de bbdd para pruebas de rendimiento.
- Auto-documentación.
- Auto-validación.
- Análisis estadísticos de los datos y de los programas.
- Inferir comportamiento de los usuarios, clientes, etc.
- Facilitar la importación y exportación de datos. Por ejemplo XBRL: lenguaje de presentación de informes de negocio extensible.
- Enlazar con ontologías estándar. Por ejemplo FIBO: ontología del negocio financiero.
- Facilitar la integración con otros sistemas.
- Razonamiento automático (machine reasoning).
Conclusión
 La representación del conocimiento esta siendo un área de investigación enfocada sobre todo en el tratamiento de los datos: estructurar la información de los buscadores, análisis semánticos aplicados al Big Data, definiciones de ontologías asociadas a diferentes negocios, etc.
La representación del conocimiento esta siendo un área de investigación enfocada sobre todo en el tratamiento de los datos: estructurar la información de los buscadores, análisis semánticos aplicados al Big Data, definiciones de ontologías asociadas a diferentes negocios, etc.
Construir metodologías de desarrollo que doten a los programas de esas capacidades es una puerta hacia el futuro con potenciales aun por descubrir.
Ver todos los posts Teórico.
La representación del conocimiento esta siendo un área de investigación enfocada sobre todo en el tratamiento de los datos: estructurar la información de los buscadores, análisis semánticos aplicados al Big Data, definiciones de ontologías asociadas a diferentes negocios, etc.Construir metodologías de desarrollo que doten a los programas de esas capacidades es una puerta hacia el futuro con potenciales aun por descubrir.
Ver todos los posts Teórico.
Language Workbench
En anteriores publicaciones vimos lo que son los DSLs y por qué son necesarios y útiles en el desarrollo de software. Una vez que decidimos apoyarnos en ellos, nos encontramos ante la necesidad de una herramienta que nos permitan diseñarlos y utilizarlos. Esta herramienta se denomina técnicamente Language Workbench (LW).
Un LW está formado por dos partes fundamentales:
Un LW está formado por dos partes fundamentales:
- Diseño del lenguaje.
- Uso del lenguaje. Programación.
Es posible que en el futuro la herramienta se divida en dos, de tal manera que, dentro o fuera de una organización, existirán dos roles perfectamente diferenciados: quienes diseñen el lenguaje y quienes se encarguen de utilizarlo, de programar en él.
Diseño del lenguaje
Un LW debe ser capaz de proveer las utilidades para definir las diferentes partes que forman el lenguaje:
Diseño del lenguaje
Un LW debe ser capaz de proveer las utilidades para definir las diferentes partes que forman el lenguaje:
- Sintaxis abstracta. La estructura gramatical/conceptual que define el lenguaje. Puede ser entendido también como el meta-modelo.
- Sintaxis concreta. La representación o representaciones visuales de dichos conceptos. Pueden ser representaciones en formato texto y/o gráfico. Para entendernos, es la definición de la interfaz visual con la que trabajará el programador.
- Semántica estática. Define aquellas restricciones o reglas que el lenguaje debe cumplir (aparte de ser sintácticamente correcto).
- Semántica dinámica. Sería sobre todo la traducción a lenguajes tradicionales aunque, como mencionaremos luego, aquí se encuentra el mayor potencial de esta metodología de desarrollo.
Uso del lenguaje
Una vez definidos los puntos anteriores, la herramienta es capaz de interpretarlos y proveernos de un entorno de desarrollo (IDE). Según sea más o menos sofisticado, a parte de la edición, nos podrá proveer de utilidades como: autocompletar, validaciones estáticas, resaltar elementos sintácticos, mostrar diferentes vistas e incluso debug.
A parte de las características anteriores, este entorno nos permitirá generar código e incluso podrá dotarnos de un proceso de building para obtener el aplicativo final.
Potencial futuro
Todo lo comentado hasta ahora nos permite tener un proceso de desarrollo análogo al tradicional pero con las ventajas que ofrecen los DSLs y la generación de código, lo cual es un enorme avance en el que se apoyan los defensores e investigadores de esta metodología.
Estando de acuerdo en lo anterior, para nosotros el verdadero potencial, aun por descubrir, es el hecho de que la programación deja de ser una mera declaración funcional y pasa a ser una representación del conocimiento. Una vez que definimos los conceptos y sus reglas, la semántica puede ser capaz de ofrecernos muchos más servicios que la simple generación de código.
Ver todos los posts Teórico.
Una vez definidos los puntos anteriores, la herramienta es capaz de interpretarlos y proveernos de un entorno de desarrollo (IDE). Según sea más o menos sofisticado, a parte de la edición, nos podrá proveer de utilidades como: autocompletar, validaciones estáticas, resaltar elementos sintácticos, mostrar diferentes vistas e incluso debug.
A parte de las características anteriores, este entorno nos permitirá generar código e incluso podrá dotarnos de un proceso de building para obtener el aplicativo final.
Potencial futuro
Todo lo comentado hasta ahora nos permite tener un proceso de desarrollo análogo al tradicional pero con las ventajas que ofrecen los DSLs y la generación de código, lo cual es un enorme avance en el que se apoyan los defensores e investigadores de esta metodología.
Estando de acuerdo en lo anterior, para nosotros el verdadero potencial, aun por descubrir, es el hecho de que la programación deja de ser una mera declaración funcional y pasa a ser una representación del conocimiento. Una vez que definimos los conceptos y sus reglas, la semántica puede ser capaz de ofrecernos muchos más servicios que la simple generación de código.
Ver todos los posts Teórico.
DSLs
Los lenguajes específicos de dominio (Domain-Specific Languages – DSLs) son lenguajes de programación diseñados para definir, de una manera más precisa y expresiva, áreas particulares, bien sean técnicas o de negocio.
Se denominan así en contraposición a los lenguajes de propósito general (General Purpose Languages – GPLs – Java, C#, C++, etc), ofreciendo un enfoque menos amplio pero más preciso, es decir, su objetivo es cubrir únicamente el área o dominio para el que se diseñan pero hacerlo con las estructuras gramaticales y/o abstracciones gráficas que mejor le definen.
Para entender estos lenguajes vamos a verlos desde dos puntos de vista: como una evolución a partir de la generación de código y como una evolución desde los GPLs.
DSLs desde la generación de código
Existen diferentes formas, más o menos sofisticadas, para generar código: macros, datos estructurados en tablas, generación dinámica, parseo de estructuras simples, modelados tipo CASE, etc, pero siempre que hablemos de un nivel elevado hablaremos de lenguajes (de tipo texto o gráfico), donde se define de manera formal las estructuras lingüísticas, su representación y su interpretación.
De este modo, entendemos que los DSLs son la vía más sofisticada en la generación de código.
DSLs desde los GPLs
Los GPLs son potentes porque permiten definir todos los problemas (Turing completo) pero en muchos casos son expresivamente pobres debido al salto entre la definición del problema (mundo real) y su solución (código fuente). Esto hace muy complicada la programación y el mantenimiento porque se hace difícil entender lo que se pretende solucionar.Pongamos por ejemplo la definición de una interfaz de usuario web y su representación en HTML: el salto expresivo es enorme.
En base a esta necesidad surgen los DSLs.
Características y ventajas de los DSLs
Se denominan así en contraposición a los lenguajes de propósito general (General Purpose Languages – GPLs – Java, C#, C++, etc), ofreciendo un enfoque menos amplio pero más preciso, es decir, su objetivo es cubrir únicamente el área o dominio para el que se diseñan pero hacerlo con las estructuras gramaticales y/o abstracciones gráficas que mejor le definen.
Para entender estos lenguajes vamos a verlos desde dos puntos de vista: como una evolución a partir de la generación de código y como una evolución desde los GPLs.
DSLs desde la generación de código
Existen diferentes formas, más o menos sofisticadas, para generar código: macros, datos estructurados en tablas, generación dinámica, parseo de estructuras simples, modelados tipo CASE, etc, pero siempre que hablemos de un nivel elevado hablaremos de lenguajes (de tipo texto o gráfico), donde se define de manera formal las estructuras lingüísticas, su representación y su interpretación.
De este modo, entendemos que los DSLs son la vía más sofisticada en la generación de código.
DSLs desde los GPLs
Los GPLs son potentes porque permiten definir todos los problemas (Turing completo) pero en muchos casos son expresivamente pobres debido al salto entre la definición del problema (mundo real) y su solución (código fuente). Esto hace muy complicada la programación y el mantenimiento porque se hace difícil entender lo que se pretende solucionar.Pongamos por ejemplo la definición de una interfaz de usuario web y su representación en HTML: el salto expresivo es enorme.
En base a esta necesidad surgen los DSLs.
Características y ventajas de los DSLs
- Mayor nivel de abstracción. Definen conceptos más complejos, más abstractos y por tanto más expresivos.
- Tienen menos grados de libertad. Normalmente no son Turing completos. Permiten definir el dominio, nada más que el dominio y con las reglas que rigen el dominio, lo cual les dota de una enorme potencia (en ese dominio, claro).
- Aumentan la productividad ya que permiten programar de una manera más rápida y eficiente.
- Mejoran la calidad del software. Abstraen de la complejidad técnica, generalmente resuelta por el generador de código, evitando errores.
- Soporte IDE (entorno de desarrollo integrado). Validaciones, comprobación de tipos, autocompletar, etc. Esto es una gran diferencia respecto a la definición del dominio mediante APIs o Frameworks.
- Independientes de la plataforma.
- En general todos las ventajas de la generación de código.
Los DSLs son comunes en el mundo real, a lo largo de la historia han sido creados en matemáticas, ciencia, medicina… Es el momento de usarlos en el desarrollo de software.
Ver todos los posts Teórico.
Ver todos los posts Teórico.
